

서비스를 이용하는 사용자들이 남기는 로그는 서비스 로그와 행동 로그로 구분된다.
로그 정의
로그란?
시스템 로그
서비스 로그
행동 로그
‘좋은 로그’를 위해 고려해야 할 것들
필요한 정보가 있는 로그
•
목표가 있는 로그
1.
목표를 한 문장으로 정의
예) 재방문율 집계가 필요하다.
2.
하나의 지표에 대해서 다양한 각도의 고민
예) 추후 재방문율 집계시 ‘국가별’, ‘레벨별’, ‘직업별’ 필터링이 필요할 것이다.
3.
목표에 따라 남겨야 할 이벤트와 그 항목들을 정의
예) 목표들의 우선순위에 따라, 점진적으로 항목을 추가하는 방향도 고려
•
일관성
◦
일관성이란?
▪
같은 구성요소에 대하여 같은 항목들을 가지는 것
◦
구성요소의 예)
▪
‘플레이어의 아이템 획득’ 이벤트의 경우,
플레이어와 아이템이라는 구성요소를 가진다.
◦
일관성이 없는 경우의 예)
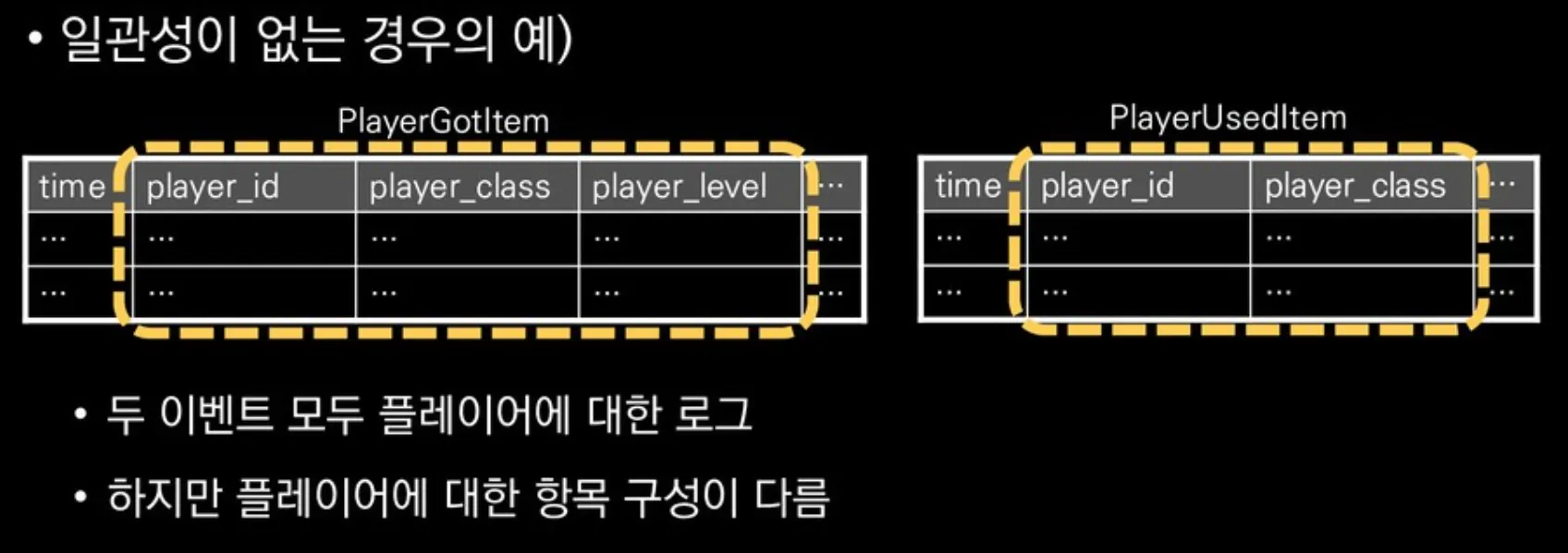
•
믿을 수 있는 로그
1.
로그가 의도한 시점에서 발생했을 것이라는 믿음
2.
의도한 대로 데이터가 남았을 것이라는 믿음
a.
의도한 것과 다른 데이터가 남을 수 있는 가능성
b.
어뷰징에 의한 변조 가능성
3.
100%는 아니더라도 납득할 수 있는 수준의 믿음을 위한 노력이 필요
의미가 명확한 로그
•
이름에 대한 합의와 규약
1.
의미를 충분히 표현할 수 있어야 함.
2.
나중에 이벤트 또는 항목의 이름을 바꾸는 것은 큰 비용이 발생할 수 있음
3.
때문에, 길더라도 구체적인 이름을 사용
a.
다른 의미와 혼동될만한 가능성을 피할 수 있다.
b.
미래에 들어가는 이름과 의미가 충돌할 가능성을 낮출 수 있다.
4.
이름을 정의하기 위한 최소 규약(Naming convention) 정의
예)

•
이벤트를 구별하는 기준
1.
‘<상태>의 시작’, ‘<상태>의 종료’
a.
상태의 시작과 종료를 이벤트로 분류하는 구조
b.
의미적으로 명확하게 구분이 가능하지만, 이벤트 종류가 많아질 수 있음.
c.
시작과 완료 시 항목 구성의 차이가 큰 경우에 적합
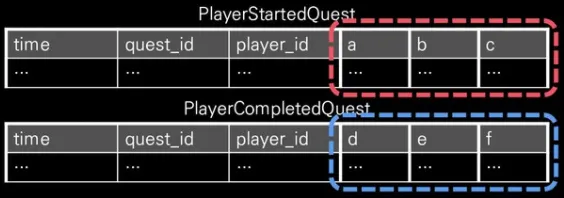
2.
‘<상태> 업데이트’
a.
로그 항목에서 상태변화의 종류를 알 수 있는 구조
b.
아래의 경우에 좀 더 편리하게 분석할 수 있음
i.
같은 구성요소에 대해 상태만 변한다.
ii.
항목 구성이 거의 비슷하다.
iii.
이력의 변화가 중요하다.
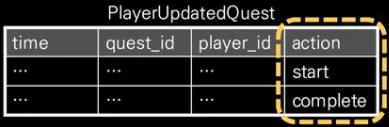
3.
한 이벤트가 억지로 여러 가지 이벤트를 포괄하지 않도록 함
a.
특정 이벤트에 대한 내용이 변경될 수 있음
b.
이벤트와 항목의 이름이 여러 가지 의미를 가지게 되어 불명확해질 수 있음
c.
데이터 타입이나 표현 방법을 통일하게 되면서, 데이터를 상세하게 남기지 못할 수 있음
4.
표현력
a.
약간의 데이터 용량 절감을 위해 축약된 표현을 사용하지 않는다.
i.
저장 비용은 크지 않고, 경우에 따라 압축이 가능하다.
ii.
득보다 실이 많을 수 있다.(생산성 저하)
b.
경우에 따라 데이터 타입에 대한 고려 또한 필요
예) 소수점 표현, 숫자 범위
5.
빈 값의 의미를 명확하게
a.
빈 값은 다양하게 해석될 수 있음
i.
해당 항목에 대한 정보가 아예 존재하지 않는 경우
ii.
실제 값이 빈 값인 경우
b.
명확하게 하는 것에 의의
편리하게 데이터를 얻을 수 있는 로그
•
로그 형식
1.
서비스 로그는 특정 항목에 대한 접근이 필요한 경우가 많음
2.
필요한 요소
a.
컴퓨터가 읽기 쉽도록 구조화된 형식
b.
사람이 읽을 수 있는 형식
3.
일반적으로 많이 쓰이는 형식
a.
JSON, key/value
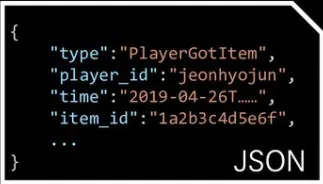
•
메타데이터 사용에 대한 충분한 고민
1.
메타데이터란?
a.
서비스를 구성하는 정보에 대하여, 식별자와 그 상세정보가 매핑된 데이터

2.
메타데이터의 남용은 관리 이슈와 생산성 저하를 유발
a.
메타데이터가 많아지면 관리하기 힘들어짐
b.
집계 시마다 로그 외의 다른 데이터를 참조해야 함
c.
때문에 본래 목표를 위한 기본적인 데이터는 로그 항목에 포함하는 것이 좋다.
3.
메타데이터 사용의 적절한 예
a.
정적 데이터가 과도하게 많고, 정의했던 로그의 목표에 필요하지 않은 경우
→ 목표에 꼭 필요한 데이터라면 로그의 항목으로 구성하는게 좋다.
b.
변경 주체가 서비스 제공자에게 있는 경우에 한하여 사용
c.
메타데이터가 불가피하게 많아질 경우
→ 시스템에서 메타데이터를 효율적으로 관리하고 사용할 수 있는 도구가 필요
4.
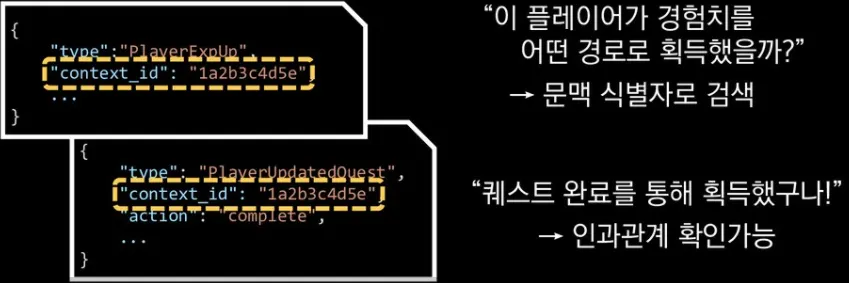
문맥 식별자와 고유 식별자
a.
문맥 식별자(Context identifier)
i.
하나의 행동으로 일어나 여러 개의 로그는 같은 문맥 식별자를 갖게 함
ii.
인과관계나 선후관계를 파악하는 데 도움을 준다.
b.
고유 식별자(unique identifier)
i.
중복 로그를 쉽게 식별할 수 있음
ii.
특정한 로그 하나를 기준으로 잡기 편리함
다른 관점에서 생각해볼 것
•
서비스에 줄 수 있는 영향
→ 서버에서 캐싱 하거나 도는 메타데이터를 활용하거나
1.
배보다 배꼽이 큰 경우가 있을 수 있음
2.
기술적인 한계를 해결하거나, 또는 적절한 타협점을 찾아야 함
예) 로그에 필요한 값을 채우는 것이 서버에 과도한 부하를 일으킬 수 있는 경우
예) 모든 유저에 대하여 n초마다 발생하는 로그
→ 샘플링하거나, 변경 시에만 남기거나
•
할 수 있는 것부터
1.
남기지 않고 있었거나, 잘못 남겨진 데이터는 깔끔히 포기한다.
2.
현 상황에서 최선의 방향을 찾는다.
3.
앞으로의 개선 방향을 논의한다.
로그 품질 관리
품질 관리가 필요한 이유
서비스 구성요소별 로그 관리
로그의 문서화
로그 유실 모니터링
로그 추가 및 변경의 프로세스화
효율적인 프로세스 진행을 위해
행동 로그 설계하기
행동 로그를 어떻게 설계하느냐에 따라서, 얻을 수 있는 정보의 수준은 완전히 달라진다.
행동 로그 설계의 핵심은 이벤트의 속성(property)을 어떤 수준으로 함께 남길 것인가? 를 정의하는 부분이다.
속성(property)
속성(property)을 남기는 수준에 따른 인사이트 수준 차이 표
BigQuery에 로그 적재하기
BigQuery에 쌓인 이벤트 로그는 아래와 같은 포맷의 스키마를 갖습니다. event에 딸린 key가 있고(위에서 설명한 event property 명칭에 해당합니다), 해당 key에 매핑된 value (event property의 구체적인 값에 해당합니다)가 있습니다. 특이한 점은 value가 자료형에 따라 구분되어 있다는 건데요. string, integer, float, double 각 자료형에 따라서 컬럼이 구분되어 있고, 추후 조회를 할 때도 자료형에 따라 정확한 컬럼을 지정해야 값을 확인할 수 있습니다. 참고로, 아래는 event property를 예로 들었지만, user property도 적재되는 방식은 동일합니다.
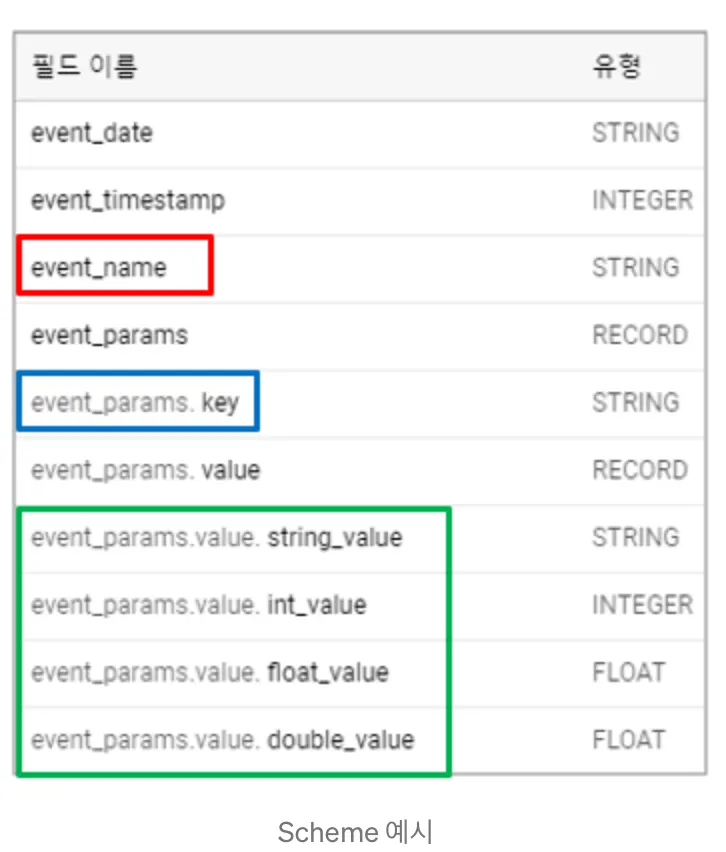
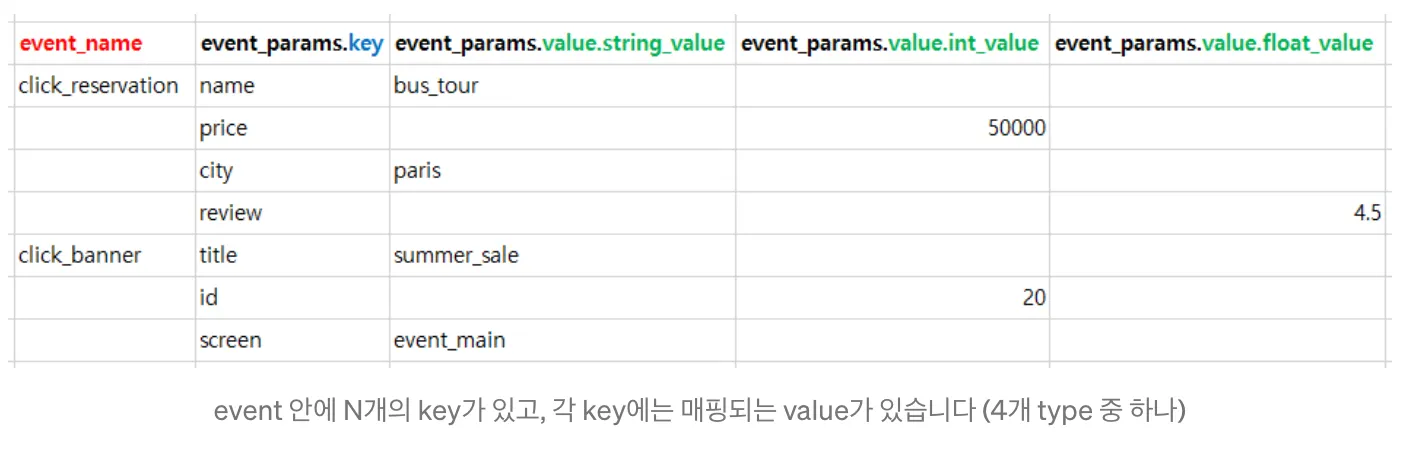
또 한가지 주목해야 하는 부분은 하나의 이벤트에 복수 개의 property가 존재하는 경우, row 안에 row가 내재한 구조로 쌓인다는 점이다. (BigQuery에서는 이런 유형의 컬럼을 Record type으로 분류합니다. 일명 nested 구조…) 간단히 설명하자면, record type의 데이터를 조회할 때는 항상 unnest 한 다음에 쿼리를 해야 한다.
nested 구조 관련 글

BigQuery에서 로그 조회하기
unnest를 활용하여 기본적인 쿼리를 작성하는 방법은 아래와 같습니다. from 문 뒤에 unnest를 이용해서 특정 record type을 임시로 펼치고, 그 컬럼을 불러와서 정보를 조회합니다.
unnest 사용 예시
위 케이스는 하나의 property를 사용하는 일반적인 상황에서 쓸 수 있는데요. 만약, 특정 record type에 있는 property 여러 개를 동시에 사용하는 쿼리를 짜고 싶다면 어떻게 해야 할까요? 가령 ‘특정 검색어’에 대해서만 ‘search_type’을 구분해서 보고 싶다면? 좀 번거롭긴 하지만 사용하려고 하는 property 개수만큼 해당 record를 unnest하면, 복수 property를 활용하는 쿼리문을 작성할 수 있습니다.
2개 이상의 property를 활용하는 쿼리
다음으로, parameter 안에 있는 value를 꺼내서 select나 group by의 기준으로 쓰고 싶다면? 아래와 같이 subquery를 이용하면 됩니다. name, key, value가 좀 헷갈릴 수 있는데, 자꾸 사용하다 보면 어쨌든 익숙해지긴 하더군요.
parameter 안에 있는 value를 사용 예시
이런 식으로 이벤트와 사용자의 property를 잘 정의해서 BigQuery에 쌓아두면 사용자의 행동 로그를 굉장히 자세한 레벨에서 분석할 수 있습니다. 기본적인 노출이나 클릭 이벤트 집계는 물론이고, 주요 페이지에 대한 퍼널 분석이라던지, 핵심 기능에 대한 사용성 확인, 신규 피쳐에 대한 A/B 테스트 성과 확인 등이 모두 가능합니다. user property를 잘 남겼다면 특정 행동을 한 유저 리스트를 추출하거나, 적합한 프로모션을 위한 세밀한 타겟팅도 할 수 있습니다.
다만 한가지 문제가 있다. nested 되어서 쌓이는 DB 구조 때문에 여러 가지 복잡한 조건이 포함된 쿼리를 작성하는 게 굉장히 어렵습니다.
기본적인 SQL 문법을 알고 있는 사람이라도 하더라도, 쿼리를 작성할 때 아래 사항을 챙기느라 꽤 시행착오를 겪어야 합니다.
•
기본적으로 unnest가 항상 필요
•
unnest하는 과정에서 불필요하게 생성되는 많은 row로 인해서 쿼리 스캔 비용이 늘어남
•
event, parameter.key, parameter.value가 매번 헷갈림
•
value의 타입이 string, integer, float, double 중 어느 것인지를 쿼리할때마다 정확히 지정해야 함
•
parameter.value를 꺼내 쓰려면 subquery 등 굉장히 복잡한 문법이 필요함
사실 정확히 말하면 Query 작성이 어려운 게 문제라기보다는, 쿼리 작성이 어려워지면서 로그를 점점 소극적으로 보게 된다는 문제가 생깁니다. 물론 빈번하게 활용되는 쿼리들은 초기에 일괄 세팅해서 편하게 볼 수 있도록 했지만, 이후 추가로 분석할만한 다양한 주제가 생겼을 때 쿼리 작성이 까다로워서 진행 자체가 늦어지거나, 세세한 데이터를 충분히 보지 못하는 경우가 종종 발생.
분석이 편한 로그 테이블 만들기
위와 같이 nested 된 테이블을 ‘사람이 보기 편한’ 형태로 flatten 하려면 어떻게 해야 할까요? 약간 복잡한 subquery를 사용해야 하지만, key를 기준으로 unnest 시키면서 value의 type을 하나하나 잘 지정해주면 그리 어렵진 않습니다.
nested된 컬럼 일괄 하기
자, 그럼 이제 이 쿼리를 기반으로 UDF(User Defined Function)를 만들고, 기존 테이블에다가 이 함수를 적용한 결과를 새 테이블로 저장하면, 놀랍도록 깔끔한 데이터셋을 얻을 수 있습니다. (이 과정을 자동화하는 pipeline은 데이터플랫폼 팀의 도움을 많이 받았습니다) 아래에 적혀진 것처럼, paramValueByKey 라는 함수를 통해 nested 된 테이블의 flatten 작업을 깔끔하게 진행하고 새로운 테이블에 저장할 수 있었습니다.
UDF 예시
이런 식으로 테이블이 깔끔하게 정리되고 나면, 똑같은 데이터를 추출하는데 필요한 쿼리도 굉장히 심플해집니다. 위에서 잠깐 언급했던 검색어별 검색 방법을 확인하는 쿼리(복수의 property를 활용했던 사례)를 예로 들어보면, before 대비 after 쿼리가 엄청나게 간결해진 것을 확인하실 수 있습니다. 저 정도면 사내 SQL 교육을 수료한 멤버들이 직접 궁금한 정보를 찾아보는데 전혀 무리가 없는 테이블 구조라고 할 수 있습니다. (데이터가 흐르는 조직!)
쿼리 예시
makrtong 빅쿼리 UDF 예시
가장 중요한 것
•
가장 중요한 것은 ‘좋은 로그’에 대한 공감대를 형성하는 것
•
가장 어렵지만 필요한 것은, 서로 다른 입장에 대하여 열린 마음을 가지는 것
•
모든 것을 만족시킬 순 없지만, 할 수 있는 것부터 하는 것이 중요
